

From Static to Dynamic: Transforming PDFs into Interactive Conversations with LLMs


Introduction
Wouldn't it be great if you'd give a PDF to your friend and ask something related from it and he looks up and gives an answer? Here your friend uses the PDF as a resource and gives his answer along with his knowledge on that topic. Now let's replace the friend with a model. The model can use the knowledge from the given PDF and also use its own and generate accurate answers. Let's look at how to create one for ourselves and understand how it works.
Architecture

Extracting Content
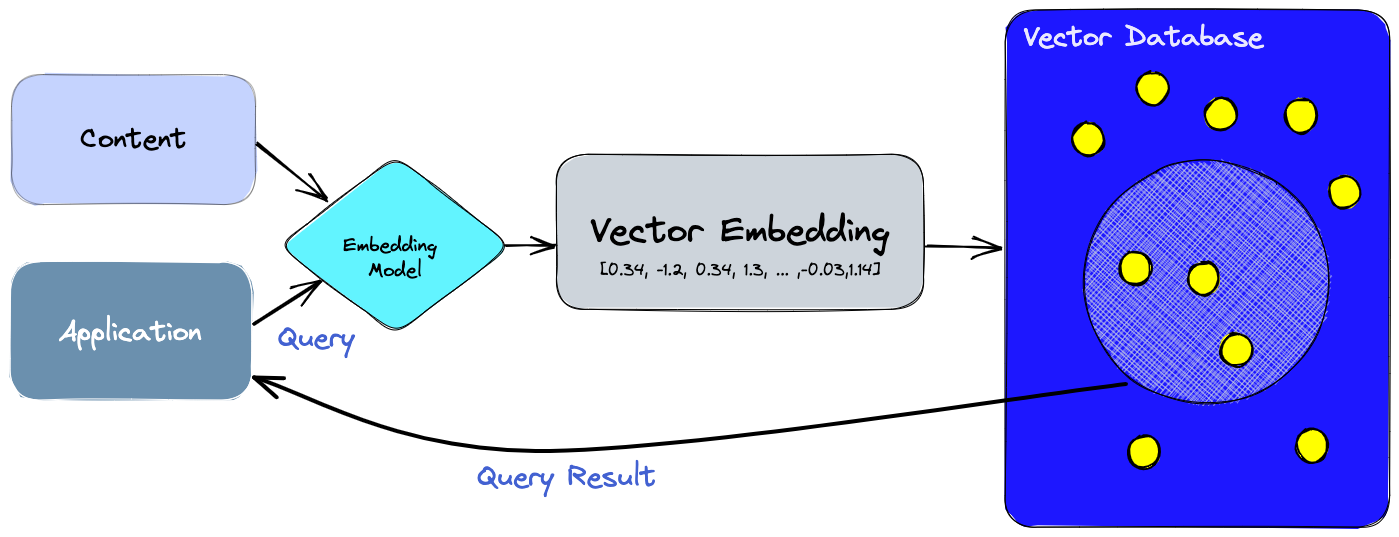
As we can see from the above flowchart the first step is to extract the content from the PDF, once the content is extracted we are left with a single large string of text from the PDF which may be very huge to handle so let's break down the string into multiple smaller chunks so that we can handle it easily. Now we need to convert the chunks into embeddings and store them in a database.
What is an Embedding?
An embedding is a way of representing complex information, like text or images, using a set of numbers. It works by translating high-dimensional vectors into a lower-dimensional space, making it easier to work with large inputs. The process involves capturing the semantic meaning of the input and placing similar inputs close together in the embedding space, allowing for easy comparison and analysis of the information. In simple terms, it's just storing our data in vector format which is then later used by the LLM to generate accurate results.
What is a Vector Database?

Vector Database is just like any other normal database but its main purpose is to store data in vector format. The embeddings that were previously generated are in vector format, so they are stored in a vector database rather than a traditional SQL or NoSQL database. Some of the popular Vector databases are Pinecone, Weaviate and ChromaDB. But there's an extension to the famous SQL database i.e. PostgreSQL that enables us to store embeddings into a traditional SQL database. PG Vector is an extension that allows us to store data which is in vector format in our SQL database along with other data.
Similarity Search
Now when the user asks any question the query first gets converted into an embedding and uses the embedding to search for similar documents by calculating the distance between the vectors(embeddings) which are stored in the vector store. This step returns documents that potentially have the answer to the query asked by the user.
Retrieval Augmented Generation
RAG is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs' generative process.
In layman's terms, Imagine you have a super-smart AI that can answer all kinds of questions and generate human-like text. This AI learns from a huge database of information. But here's the thing, that information can get old, like an old encyclopedia.
RAG is like a special tool for this AI. It helps the AI check the latest and most accurate information from the internet, just like how you'd Google something to get the most recent answer. RAG also shows you how the AI comes up with its answers, so you can understand how it thinks.
So, in a nutshell, RAG is a tool that makes the super-smart AI even smarter by giving it access to fresh knowledge from the internet and helping you see how it works its magic. Here we are using RAG which takes the uploaded PDF as the primary source of knowledge and then generate accurate result.

Streamlit App
Let's create a simple app using Streamlit and Flan-T5 as the LLM from Huggingface
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub
def main():
load_dotenv()
st.set_page_config(page_title="AskIt!!")
st.header("Ask your pdf :books:")
pdf = st.file_uploader("Upload your PDF",type="pdf")
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len
)
chunks = text_splitter.split_text(text)
embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-base")
knowledge_base = FAISS.from_texts(chunks, embeddings)
user_query = st.text_input("Ask your question")
if user_query:
docs = knowledge_base.similarity_search(user_query)
llm = HuggingFaceHub(repo_id="google/flan-t5-large", model_kwargs={"temperature":0, "max_length":512})
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=docs, question=user_query)
st.write(response)
if __name__ == '__main__':
main()
We need to first install the required libraries like streamlit, PyPDF2, langchain, sentence-transformer and dotenv. Make sure to store the HuggingFace API token in a .env file as shown below
HUGGINGFACEHUB_API_TOKEN="YOUR_API_TOKEN"
The code is self-explanatory, we are using the streamlit to create a UI to upload the PDF which then uses the hkunlp/instructor-base to create the embeddings and stores in knowledge_base which acts as the vector store here, using this vector store and using google/flan-t5-large LLM we are generating the answers.

Thank you for reading the article. If you found it informative or interesting, please give it a thumbs up. I would highly appreciate it if you could share it with your friends as well.